
May tải dữ liệu
Gato GraphQL sử dụng các thành phần phía máy chủ để biểu diễn mô hình dữ liệu (không phải đồ thị hay cây). Hãy cùng xem cách nó thực thi quá trình tải dữ liệu để giải quyết GraphQL query.
Để xử lý dữ liệu, chúng ta phải làm phẳng các thành phần thành các kiểu (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), sắp xếp chúng theo thứ tự xuất hiện trong hệ thống phân cấp thành phần (Director, rồi Film, rồi Actor) và xử lý chúng theo từng "vòng lặp", lấy dữ liệu đối tượng cho từng kiểu trong vòng lặp riêng của nó, như sau:

Máy tải dữ liệu của máy chủ phải triển khai (giả-)thuật toán sau để tải dữ liệu:
Chuẩn bị:
- Chuẩn bị một hàng đợi rỗng để lưu danh sách ID của các đối tượng cần lấy từ cơ sở dữ liệu, được tổ chức theo kiểu (mỗi mục sẽ là:
[type => danh sách ID]) - Lấy ID của đối tượng đạo diễn nổi bật, và đặt vào hàng đợi dưới kiểu
Director
Vòng lặp cho đến khi không còn mục nào trong hàng đợi:
- Lấy mục đầu tiên trong hàng đợi: kiểu và danh sách ID (ví dụ:
Directorvà[2]), rồi xóa mục này khỏi hàng đợi - Sử dụng đối tượng
TypeDataLoadercủa kiểu, thực thi một query duy nhất đối với cơ sở dữ liệu để lấy tất cả các đối tượng của kiểu đó với những ID đó - Nếu kiểu có các trường quan hệ (ví dụ: kiểu
Directorcó trường quan hệfilmsthuộc kiểuFilm), thì thu thập tất cả ID từ các trường này từ tất cả các đối tượng được lấy trong vòng lặp hiện tại (ví dụ: tất cả ID trong trườngfilmstừ tất cả đối tượng của kiểuDirector), và đặt các ID này vào hàng đợi dưới kiểu tương ứng (ví dụ: ID[3, 8]dưới kiểuFilm).
Khi kết thúc các vòng lặp, chúng ta sẽ đã tải tất cả dữ liệu đối tượng cho tất cả các kiểu, như sau:
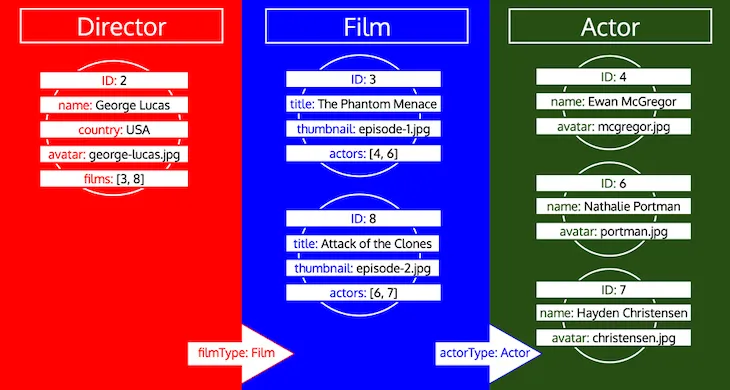
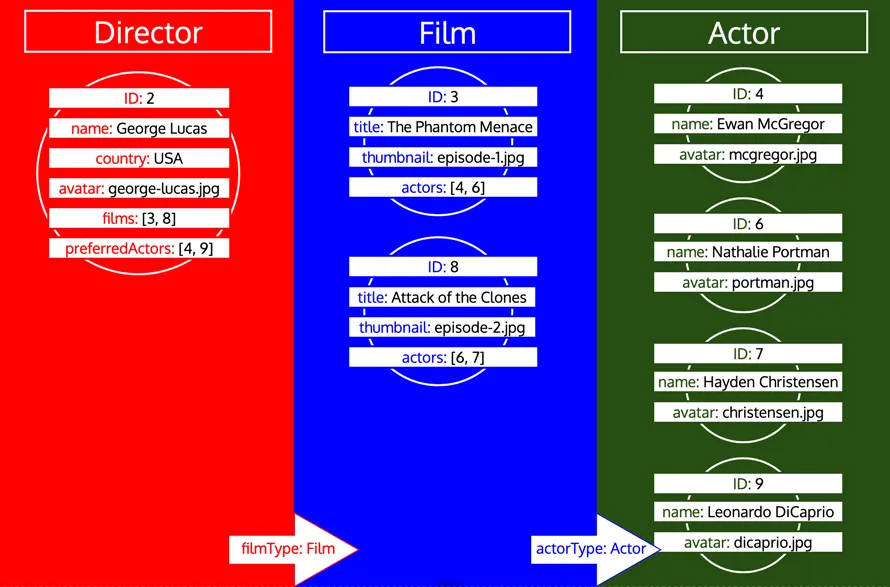
Hãy chú ý rằng tất cả ID của một kiểu được thu thập cho đến khi kiểu đó được xử lý trong hàng đợi. Ví dụ, nếu chúng ta thêm trường quan hệ preferredActors vào kiểu Director, các ID này sẽ được thêm vào hàng đợi dưới kiểu Actor, và sẽ được xử lý cùng với các ID từ trường actors của kiểu Film:
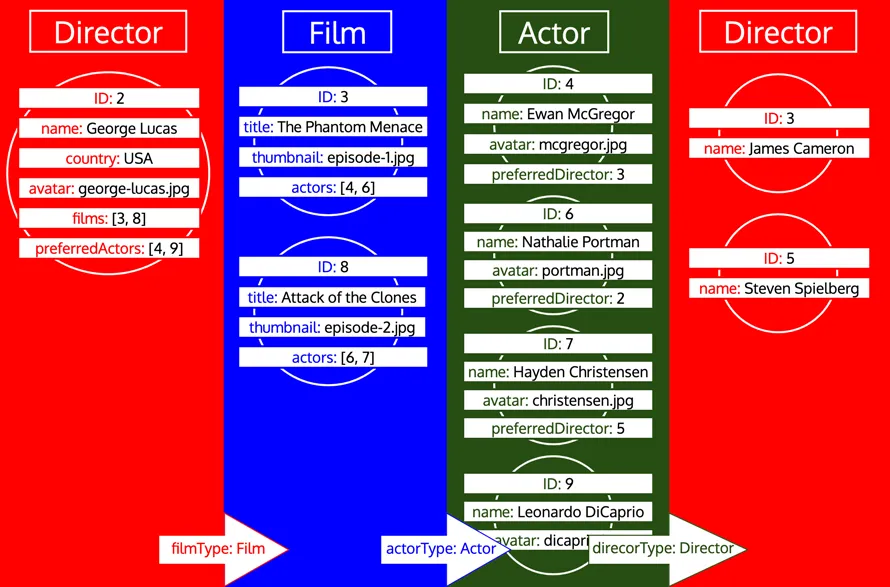
Tuy nhiên, nếu một kiểu đã được xử lý và sau đó chúng ta cần tải thêm dữ liệu từ kiểu đó, thì đó là một vòng lặp mới trên kiểu đó. Ví dụ, thêm trường quan hệ preferredDirector vào kiểu Author sẽ khiến kiểu Director được thêm vào hàng đợi một lần nữa:
Bây giờ khi đã lấy tất cả dữ liệu đối tượng, chúng ta cần định hình nó thành phản hồi mong đợi, phản ánh GraphQL query. Tuy nhiên, như có thể thấy, dữ liệu không có cấu trúc cây như yêu cầu. Thay vào đó, các trường quan hệ chứa ID của đối tượng lồng nhau, mô phỏng cách dữ liệu được biểu diễn trong cơ sở dữ liệu quan hệ. Do đó, theo sự so sánh này, dữ liệu được lấy cho mỗi kiểu có thể được biểu diễn dưới dạng bảng, như sau:
Bảng cho kiểu Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Bảng cho kiểu Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Bảng cho kiểu Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Khi có tất cả dữ liệu được tổ chức dưới dạng bảng, và biết cách mỗi kiểu liên quan đến nhau (tức là Director tham chiếu đến Film qua trường films, Film tham chiếu đến Actor qua trường actors), máy chủ GraphQL có thể dễ dàng chuyển đổi dữ liệu sang dạng cây mong đợi:
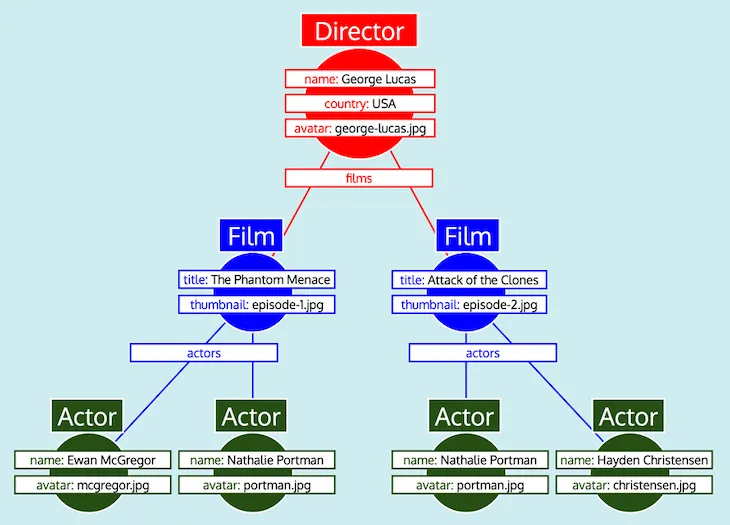
Cuối cùng, máy chủ GraphQL xuất ra cây, có dạng của phản hồi mong đợi:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Phân tích độ phức tạp thời gian của giải pháp
Hãy phân tích ký hiệu O lớn của thuật toán tải dữ liệu để hiểu số lượng queries thực thi đối với cơ sở dữ liệu tăng như thế nào khi số lượng đầu vào tăng, nhằm đảm bảo rằng giải pháp này có hiệu suất tốt.
Máy tải dữ liệu tải dữ liệu theo các vòng lặp tương ứng với từng kiểu. Vào thời điểm bắt đầu một vòng lặp, nó đã có danh sách tất cả ID của tất cả các đối tượng cần lấy, do đó có thể thực thi 1 query duy nhất để lấy tất cả dữ liệu cho các đối tượng tương ứng. Từ đó suy ra rằng số lượng queries đến cơ sở dữ liệu sẽ tăng tuyến tính với số lượng kiểu liên quan đến query. Nói cách khác, độ phức tạp thời gian là O(n), trong đó n là số kiểu trong query (tuy nhiên, nếu một kiểu được lặp lại nhiều lần, thì nó phải được tính nhiều lần vào n).
Giải pháp này có hiệu suất rất tốt, tốt hơn nhiều so với độ phức tạp hàm mũ được dự kiến khi xử lý đồ thị, hoặc độ phức tạp logarit được dự kiến khi xử lý cây.
Mã PHP được triển khai
Quá trình tải dữ liệu diễn ra trong hàm getComponentData của lớp Engine trong gói Component Model.