
Pipeline chỉ thị
Các chỉ thị được đặt trong một pipeline và thực thi theo thứ tự. Thiết kế ban đầu của chúng khá đơn giản, như sau:

Trong kiến trúc này:
- Đầu vào của pipeline là giá trị trường được cung cấp bởi field resolver
- Mỗi chỉ thị thực hiện logic của nó và chuyển kết quả sang chỉ thị tiếp theo trong pipeline
- Đầu ra của pipeline sẽ là giá trị trường đã được giải quyết, sau khi được xử lý bởi tất cả các chỉ thị
Tuy nhiên, kiến trúc này chưa khai thác tối đa sức mạnh của GraphQL. Dưới đây là mô tả tất cả các giai đoạn từ pipeline chỉ thị thực tế, cho đến thiết kế thực sự được triển khai trong Gato GraphQL.
Các chỉ thị là khối xây dựng của quá trình giải quyết query
Ban đầu, chúng ta có thể cân nhắc việc để máy chủ GraphQL giải quyết trường thông qua một cơ chế nào đó, sau đó truyền giá trị này làm đầu vào cho pipeline chỉ thị.
Tuy nhiên, sẽ đơn giản hơn nhiều nếu có một cơ chế duy nhất xử lý tất cả mọi thứ: việc gọi các field resolver (cả để xác thực lẫn giải quyết trường) đã có thể được thực hiện thông qua pipeline chỉ thị. Trong trường hợp này, pipeline chỉ thị là cơ chế duy nhất được sử dụng để giải quyết query.
Vì lý do này, máy chủ Gato GraphQL được trang bị hai chỉ thị đặc biệt:
@validategọi field resolver để xác thực rằng trường có thể được giải quyết (ví dụ: cú pháp đúng, trường tồn tại, v.v.)- Nếu thành công,
@resolveValueAndMergesau đó gọi field resolver để giải quyết trường và hợp nhất giá trị vào đối tượng phản hồi
Hai chỉ thị này thuộc loại đặc biệt "hệ thống": chúng được dành riêng cho bộ máy GraphQL và được ngầm định áp dụng trên mọi trường. (Ngược lại, các chỉ thị tiêu chuẩn là tường minh: chúng được người dùng thêm vào query.)
Bằng cách sử dụng hai chỉ thị này, query sau:
query {
field1
field2 @directiveA
}...sẽ được giải quyết như query này:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Pipeline bây giờ trông như thế này (lưu ý rằng pipeline nhận trường làm đầu vào, không phải giá trị đã được giải quyết ban đầu của nó):

Các slot của pipeline
Các chỉ thị thường được thực thi sau @resolveValueAndMerge, vì chúng hầu hết liên quan đến việc cập nhật giá trị của trường đã được giải quyết. Tuy nhiên, có những chỉ thị khác phải được thực thi trước @validate, hoặc giữa @validate và @resolveValueAndMerge.
Ví dụ:
- Để đo thời gian thực thi giải quyết một trường, chỉ thị
@traceExecutionTimecó thể lấy thời gian hiện tại trước và sau khi trường được giải quyết, bằng cách đặt các chỉ thị con@startTracingExecutionTimeở đầu và@endTracingExecutionTimeở cuối pipeline - Một chỉ thị
@cachephải kiểm tra xem một trường được yêu cầu có trong bộ nhớ đệm không và trả về phản hồi đó ngay lập tức, trước khi thực thi@resolveValueAndMerge
Pipeline sau đó sẽ cung cấp năm slot khác nhau thông qua lớp PipelinePositions, và chỉ thị sẽ chỉ định slot nào nó phải được thực thi:
- Slot
"beginning": ở ngay đầu - Slot
"before-validate": trước khi quá trình xác thực diễn ra - Slot
"middle": sau khi xác thực và trước khi giải quyết trường - Slot
"after-resolve": sau khi giải quyết trường - Slot
"end": ở ngay cuối
Pipeline chỉ thị bây giờ trông như thế này (chỉ xét 3 giai đoạn để đơn giản hóa):

Hãy chú ý cách các chỉ thị @skip và @include có thể được đáp ứng dễ dàng với kiến trúc này: được đặt trong slot "middle", chúng có thể thông báo cho chỉ thị @resolveValueAndMerge (cùng với tất cả các chỉ thị ở các giai đoạn sau trong pipeline) không thực thi bằng cách đặt cờ skipExecution thành true.
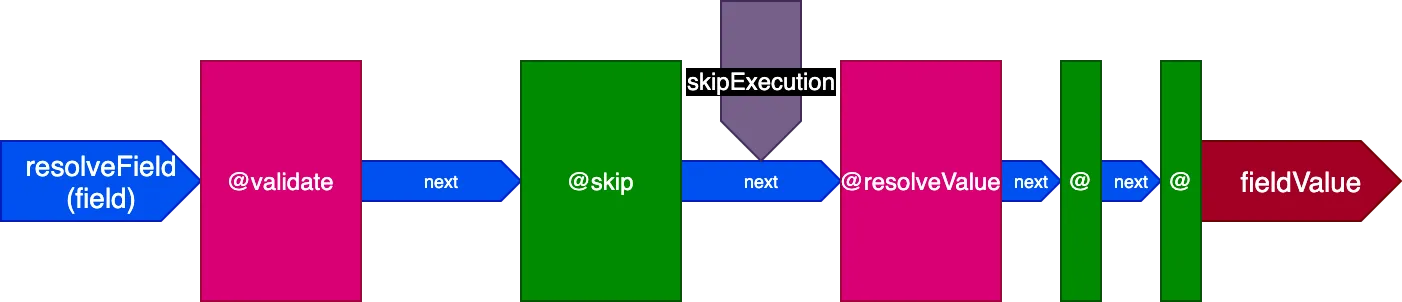
Thực thi chỉ thị trên nhiều trường trong một lần gọi
Cho đến nay, chúng ta đã xem xét một trường duy nhất được đưa vào pipeline chỉ thị. Tuy nhiên, trong một query GraphQL điển hình, chúng ta sẽ nhận được nhiều trường để thực thi các chỉ thị.
Ví dụ, trong query dưới đây, chỉ thị @upperCase được thực thi trên các trường "field1" và "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Hơn nữa, vì bộ máy GraphQL thêm các chỉ thị hệ thống @validate và @resolveValueAndMerge vào mọi trường trong query, để query này:
query {
field1
field2
field3
}...được giải quyết như query này:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Thì, các chỉ thị hệ thống sẽ luôn nhận tất cả các trường làm đầu vào.
Kết quả là, pipeline chỉ thị được thiết kế để nhận nhiều trường làm đầu vào, chứ không chỉ một trường mỗi lần:

Kiến trúc này hiệu quả hơn, bởi vì thực thi một chỉ thị chỉ một lần cho tất cả các trường nhanh hơn so với thực thi nó một lần cho mỗi trường, và sẽ tạo ra cùng kết quả.
Ví dụ, khi xác thực xem người dùng đã đăng nhập để cấp quyền truy cập vào schema, thao tác chỉ cần thực thi một lần. Chạy đoạn code sau:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}hiệu quả hơn so với chạy đoạn code này:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Điều này có vẻ không quan trọng khi gọi một hàm cục bộ như isUserLoggedIn, tuy nhiên nó có thể tạo ra sự khác biệt lớn khi tương tác với các dịch vụ bên ngoài, chẳng hạn như khi giải quyết các REST endpoint thông qua GraphQL. Trong những trường hợp này, thực thi một hàm một lần thay vì nhiều lần có thể tạo ra sự khác biệt giữa việc có thể cung cấp một chức năng nhất định hay không.
Hãy xem một ví dụ. Khi tương tác với Google Translate thông qua một chỉ thị @translate, API GraphQL phải thiết lập kết nối qua mạng. Khi đó, việc thực thi đoạn code này sẽ nhanh nhất có thể:
googleTranslateFields([$field1, $field2, $field3]);Ngược lại, thực thi hàm riêng lẻ nhiều lần sẽ tạo ra độ trễ cao hơn dẫn đến thời gian phản hồi lâu hơn, làm giảm hiệu suất của API. Có thể điều này không tạo ra sự khác biệt lớn khi dịch 3 chuỗi (trong đó trường là chuỗi cần dịch), nhưng với 100 chuỗi trở lên, nó chắc chắn sẽ có tác động:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Ngoài ra, việc thực thi một hàm một lần với tất cả đầu vào có thể tạo ra phản hồi tốt hơn so với thực thi hàm trên mỗi trường độc lập. Sử dụng lại Google Translate làm ví dụ, bản dịch sẽ chính xác hơn khi chúng ta cung cấp càng nhiều dữ liệu cho dịch vụ.
Ví dụ, khi thực thi đoạn code dưới đây:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Ở lần thực thi độc lập đầu tiên, Google không biết ngữ cảnh của "fork", vì vậy nó có thể trả lời fork là dụng cụ ăn, là ngã rẽ của con đường, hoặc một nghĩa khác. Tuy nhiên, nếu thay vào đó chúng ta thực thi:
googleTranslate(["fork", "road", "sign"]);Từ lượng thông tin phong phú hơn này, Google có thể suy ra rằng "fork" đề cập đến ngã rẽ của con đường và trả về bản dịch chính xác.
Đó là lý do tại sao các chỉ thị trong pipeline nhận tất cả các trường đầu vào cùng một lúc, và sau đó mỗi chỉ thị có thể quyết định cách tốt nhất để chạy logic của nó trên các đầu vào này (thực thi một lần cho mỗi đầu vào, thực thi một lần bao gồm tất cả đầu vào, hoặc bất kỳ cách nào ở giữa).
Pipeline bây giờ trông như thế này:
Thực thi một pipeline chỉ thị duy nhất cho toàn bộ query
Vừa rồi chúng ta đã biết rằng việc thực thi nhiều trường cho mỗi chỉ thị là hợp lý, tuy nhiên điều này hoạt động tốt miễn là tất cả các trường có cùng các chỉ thị được áp dụng. Khi các chỉ thị khác nhau, nó có thể dẫn đến độ phức tạp lớn hơn khiến việc triển khai trở nên khó khăn, và sẽ làm giảm một số lợi ích đã đạt được.
Hãy xem điều này xảy ra như thế nào. Hãy xét query sau:
query {
field1 @directiveA
field2
field3
}Chỉ thị này tương đương với chỉ thị sau:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Trong kịch bản này, các trường field2 và field3 có cùng tập hợp chỉ thị, và field1 có một tập hợp khác, do đó chúng ta sẽ phải tạo ra 2 pipeline khác nhau để giải quyết query:
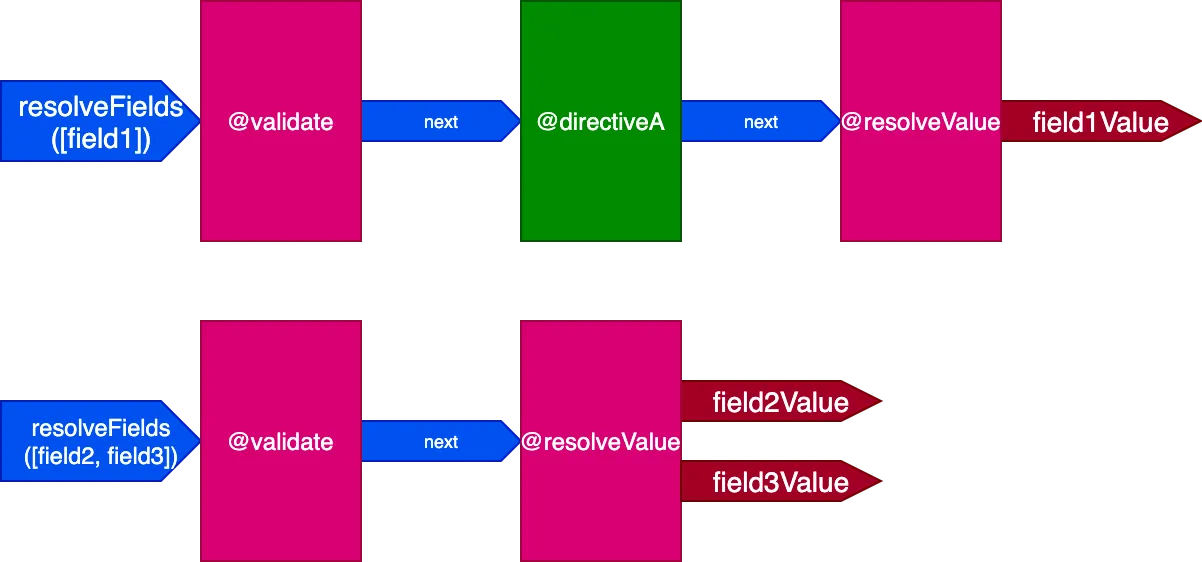
Và khi tất cả các trường có một tập hợp chỉ thị duy nhất, hiệu ứng càng rõ rệt hơn. Hãy xét query này:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Tương đương với:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}Trong tình huống này, chúng ta sẽ có 3 pipeline để xử lý 3 trường, như sau:
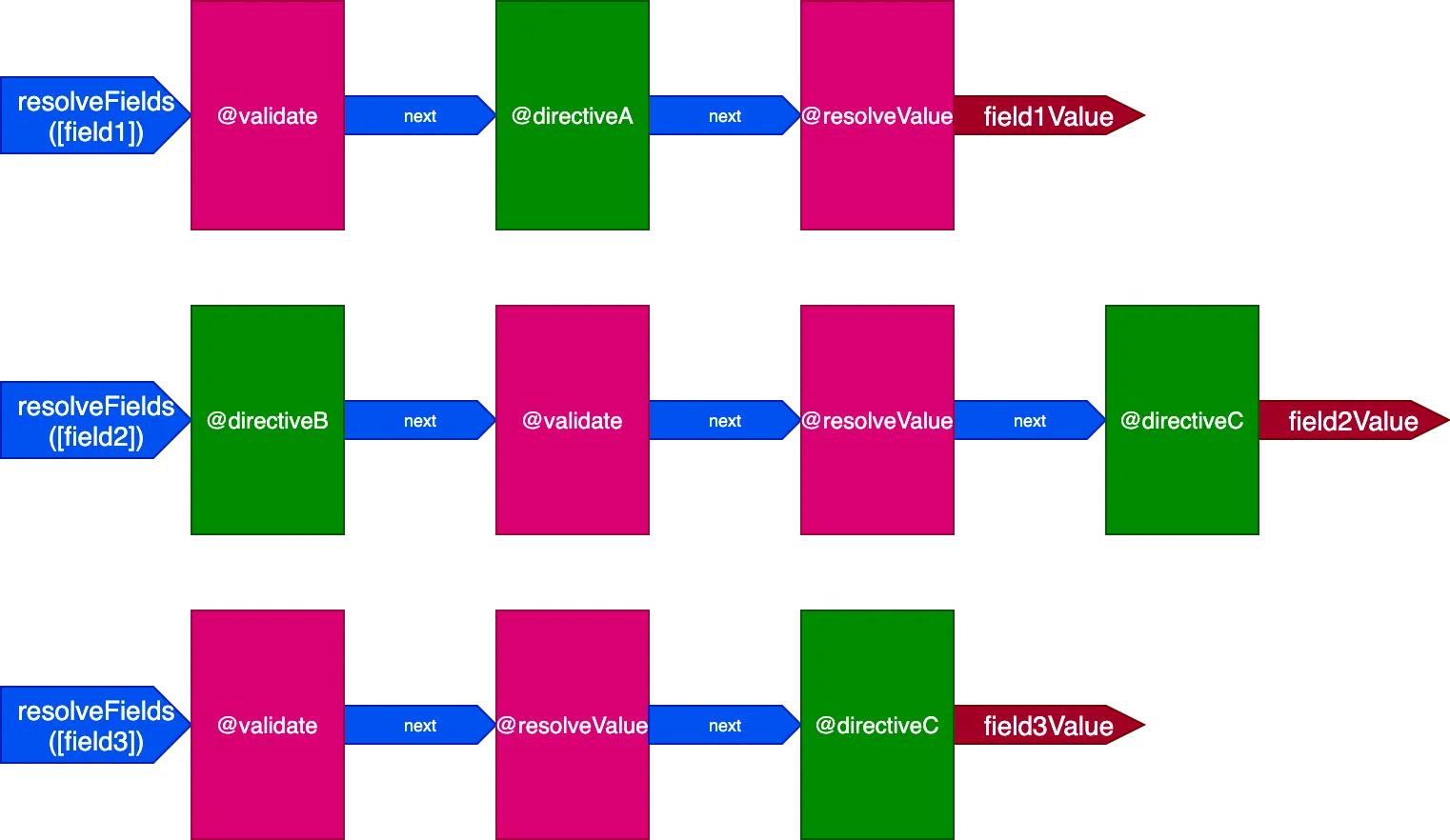
Trong trường hợp này, mặc dù các chỉ thị @validate và @resolveValueAndMerge được áp dụng trên 3 trường, nhưng vì chúng được thực thi thông qua 3 pipeline chỉ thị khác nhau, chúng sẽ được thực thi độc lập với nhau, điều này đưa chúng ta trở lại việc có một chỉ thị được thực thi trên một mục đơn mỗi lần.
Giải pháp cho vấn đề này là tránh tạo ra nhiều pipeline, mà thay vào đó xử lý bằng một pipeline duy nhất cho tất cả các trường. Kết quả là, bộ máy không còn truyền các trường làm đầu vào cho pipeline nữa, vì không phải tất cả các chỉ thị từ một pipeline duy nhất sẽ tương tác với cùng một tập hợp các trường; thay vào đó, mỗi chỉ thị phải nhận danh sách trường của riêng nó làm đầu vào của chính nó.
Thì, cho query này:
query {
field1 @directiveA
field2
field3
}...các chỉ thị @validate và @resolveValueAndMerge sẽ nhận cả 3 trường làm đầu vào, và directiveA sẽ chỉ nhận "field1":
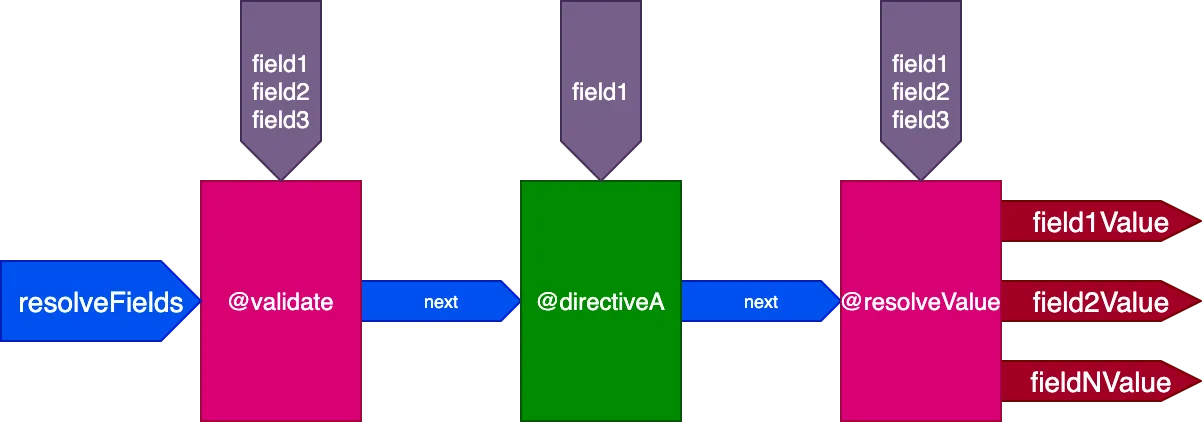
Và cho query này:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...các chỉ thị @validate và @resolveValueAndMerge sẽ nhận cả 3 trường làm đầu vào, directiveA sẽ chỉ nhận "field1", directiveB sẽ chỉ nhận "field2", và directiveC sẽ nhận "field2" và "field3":
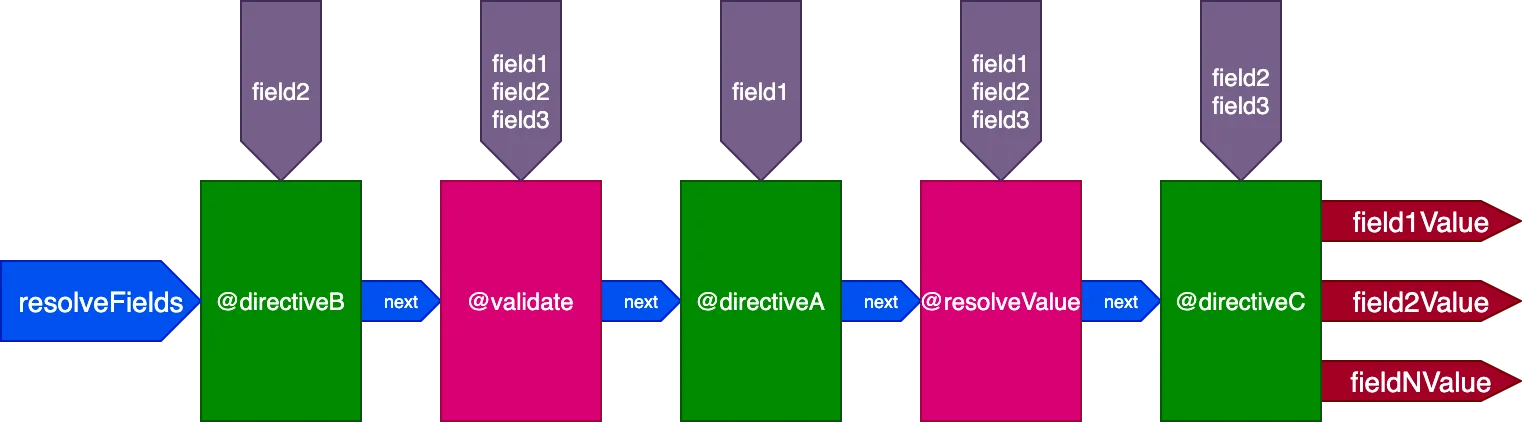
Kiểm soát thực thi chỉ thị theo từng ID
Cho đến nay, một chỉ thị ở một giai đoạn nào đó có thể ảnh hưởng đến việc thực thi các chỉ thị ở các giai đoạn sau thông qua một cờ skipExecution. Tuy nhiên, cờ này không đủ chi tiết cho tất cả các trường hợp.
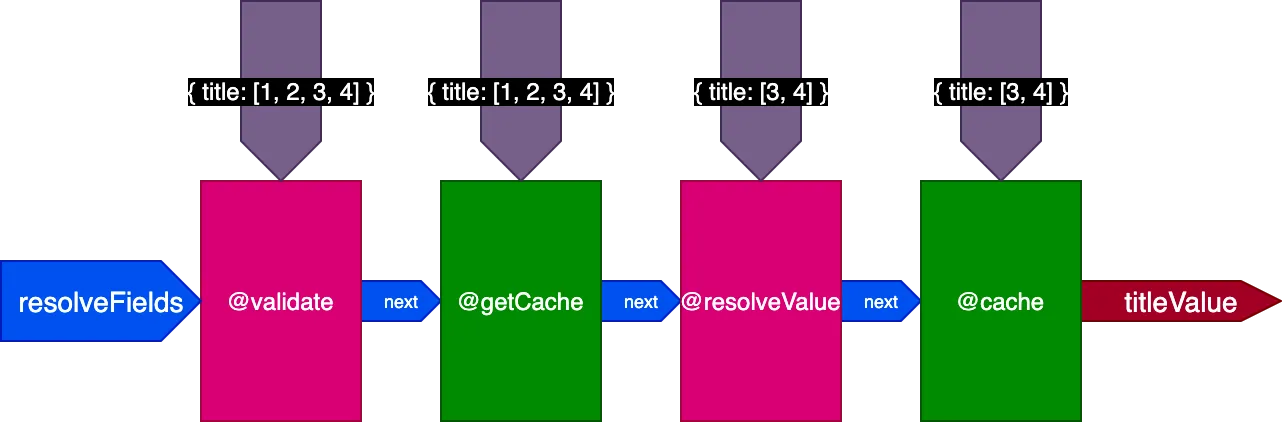
Ví dụ, hãy xét một chỉ thị @cache, được đặt trong slot "end" để lưu trữ giá trị trường, để lần sau khi trường được truy vấn, giá trị của nó có thể được lấy từ bộ nhớ đệm thông qua một chỉ thị @getCache được đặt trong slot "middle":
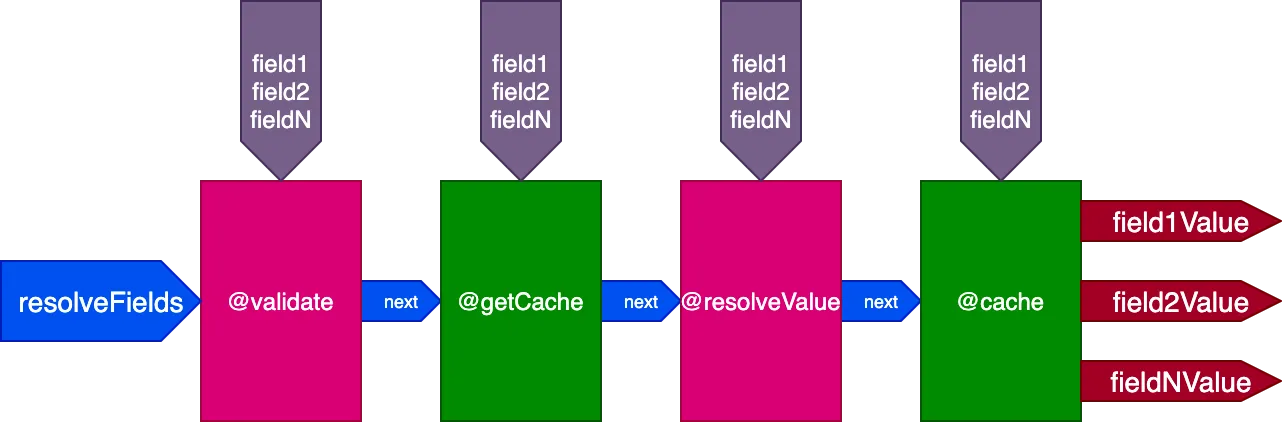
Khi thực thi query này:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Máy chủ sẽ lấy và lưu bộ nhớ đệm 2 bản ghi. Sau đó, chúng ta thực thi cùng một query, nhưng áp dụng cho 4 bản ghi:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Khi thực thi query thứ 2 này, 2 bản ghi từ query thứ 1 đã được lưu trong bộ nhớ đệm, nhưng 2 bản ghi còn lại thì chưa. Tuy nhiên, chúng ta sẽ cần tất cả 4 bản ghi đã được lưu trong bộ nhớ đệm để sử dụng cờ skipExecution. Sẽ tốt hơn nếu chúng ta có thể lấy 2 bản ghi đầu từ bộ nhớ đệm và chỉ giải quyết 2 bản ghi còn lại.
Vì vậy, chúng ta cập nhật lại thiết kế của pipeline. Chúng ta loại bỏ cờ skipExecution, và thay vào đó truyền cho mỗi chỉ thị danh sách ID đối tượng theo trường mà chỉ thị phải được áp dụng, thông qua một đầu vào đối tượng fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Biến fieldIDs là duy nhất cho mỗi chỉ thị, và mỗi chỉ thị có thể sửa đổi phiên bản fieldIDs cho tất cả các chỉ thị ở các giai đoạn sau. Do đó, skipExecution có thể được thực hiện chi tiết theo từng ID, bằng cách đơn giản là xóa ID khỏi fieldIDs cho tất cả các chỉ thị tiếp theo trong ngăn xếp.
Pipeline bây giờ trông như thế này:
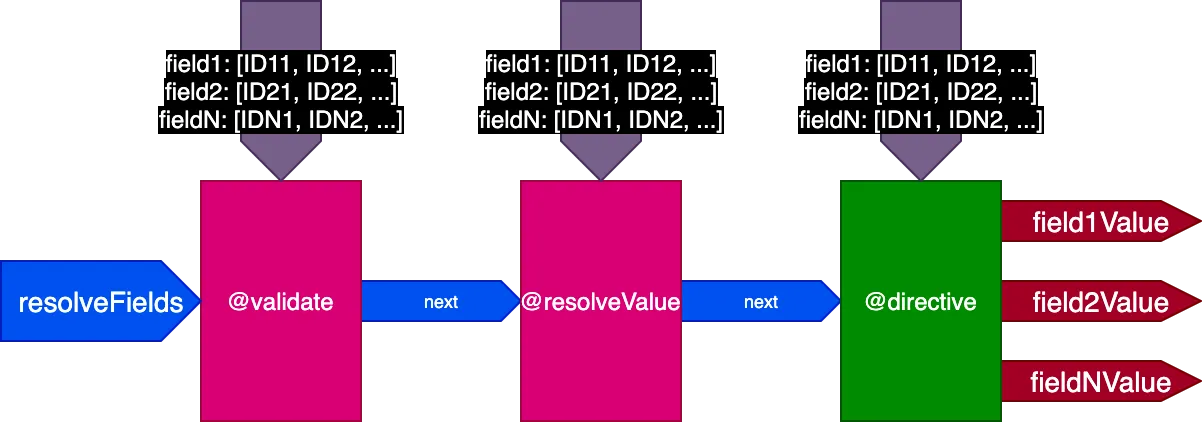
Áp dụng vào ví dụ trước, khi thực thi query đầu tiên dịch 2 bản ghi, pipeline trông như thế này:
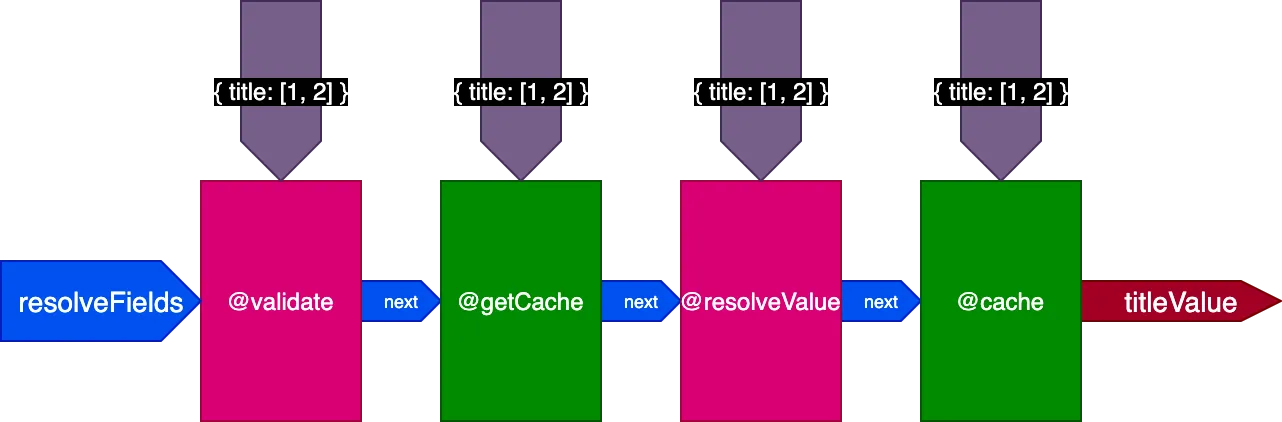
Khi thực thi query thứ hai dịch 4 bản ghi, chỉ thị @getCache nhận các ID cho cả 4 bản ghi, nhưng cả @resolveValueAndMerge và @cache chỉ nhận các ID cho 2 bản ghi cuối (chưa được lưu trong bộ nhớ đệm):
Kết hợp tất cả lại
Đây là thiết kế cuối cùng của pipeline chỉ thị:
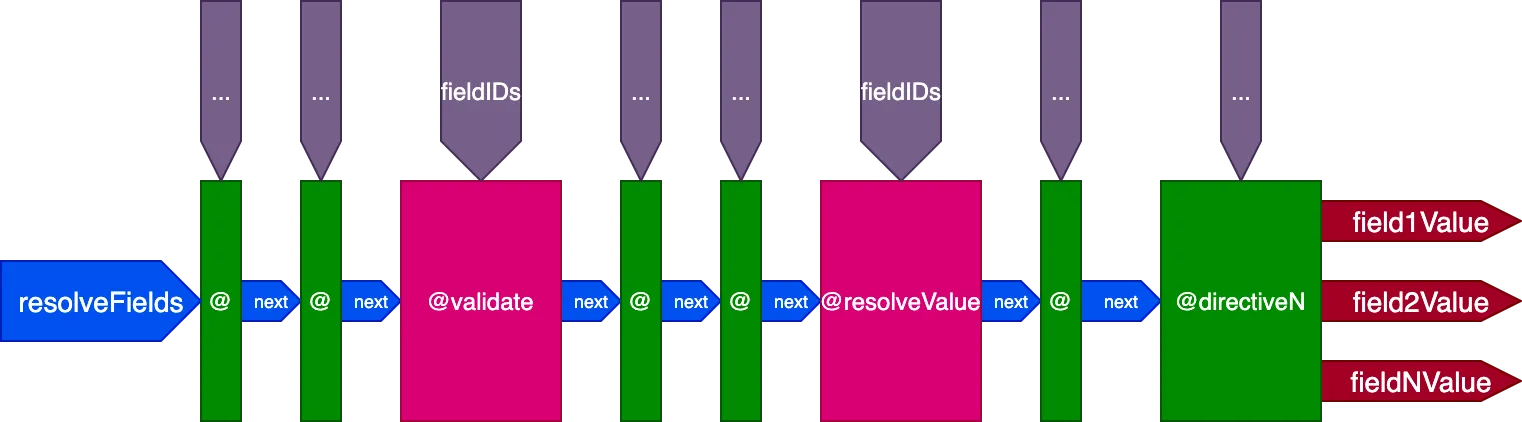
Tóm lại, đây là các đặc điểm của nó:
- Các field resolver được gọi từ bên trong pipeline chỉ thị, thông qua các chỉ thị
@validatevà@resolveValueAndMerge - Các chỉ thị có thể được đặt trong bất kỳ slot nào trong 5 slot:
"beginning","before-validate","middle","after-validate"và"end" - Các chỉ thị giải quyết nhiều trường trong một lần gọi
- Một pipeline duy nhất chứa tất cả các chỉ thị liên quan đến query
- Mỗi chỉ thị nhận tập hợp ID riêng của mình để giải quyết theo trường thông qua biến
fieldIDs - Các chỉ thị có thể sửa đổi biến
fieldIDscho tất cả các chỉ thị ở giai đoạn sau trong pipeline